


What’s next for companies in data management? It has become a crucial aspect of business operations in the current age of digital transformation. The management of data is not just about dealing with the increasing volume of data, but also about maximizing the value of data that companies manage. In the last year, companies have been evaluating what is next in their data transformation. They are looking for ways to optimize and scale their data management processes and gain competitive advantages through innovative approaches.
This is not something new but yet another cycle of evolution of the data management space. From databases to data warehouses to Hadoop-based big data platforms and data lakes, we are now at a new key cycle of data management. But there is something new about this cycle that we haven’t seen before. While historically the “what’s next” question to data management normally had one single answer or was a linear process (database --> data warehouse --> big data platform --> data lake), today we see the “what’s next” question branching into three answers:
-
Evolve or rather simplify the architecture to a data lakehouse.
-
Deliver data as a service through a data fabric or a similar solution.
-
Deliver data as a product using a data mesh design or something similar.
Though all different, they all share a common objective: to unify the data ecosystem and standardize the way data is consumed.
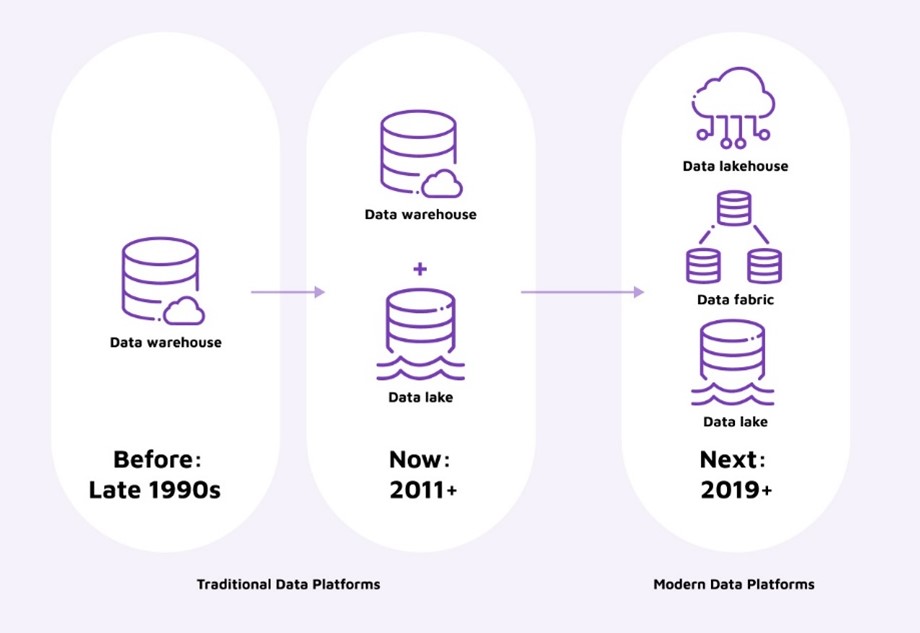
Figure 1. A timeline of how data platforms were used over the years
Data management paradigms:
Why now? All these three data management paradigms are actually not new. They have existed for a few years already, but it was possibly last year and especially this year that we started seeing companies implement or consider implementing one of these three solutions. Why now? The answer lies not only in the need to handle the increasing volume and complexity of data but also in the desire and pressure for companies to maximize the value of their data assets. Traditional data warehousing is no longer sufficient for companies that want to unlock the full potential of their data. Technology advancement, especially now with generative AI, has also facilitated some of these solutions to be more mature and feasible compared to a few years back.
A key inflection point happened last year with the explosion of the data mesh concept. Data mesh was led and promoted by its founder, Zhamak Dehghani, in her book, which, for sure, reached record sales during 2022. The concept gained a significant interest from many organizations that sought to understand what was behind this new promise of scaling value of data and how to break through the common centralized data platform bottlenecks by using a modern distributed architecture.
Data mesh soon got challenged by those that, though supportive of the need for a new scalable data management model, did not see this paradigm working in its purest form. This had a direct impact on the rebirth of the data fabric concept, which surely benefited from the momentum of the decentralization mentality, and the lakehouse concept as an option for companies who were skeptical of the data decentralization concept and were rather looking for a natural evolution of their centralized data management design.
Which is the right data management paradigm for my business?
All these options could very well require a considerable architecture and/or organizational change and are complementary to each other, so organizations should carefully evaluate their specific needs and challenges in order to decide which is the best solution for them. There is no one single answer to the “what’s next” question and the best solution for an organization might require a combination of the options described below. It is important though to understand what each of these concepts provide and decide on the right design. This article aims to provide a technology/vendor-agnostic point of view of these three paradigms as guidance and first step in deciding the best option for your organization.
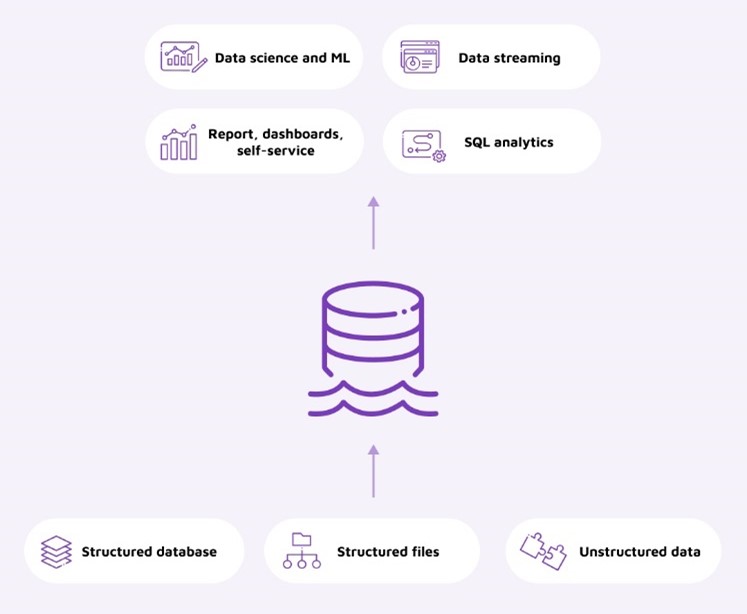
Figure 2. A sample visualization of a data lakehouse
Data lakehouse or (augmented) unified data and analytics platform
Data lakehouse in a nutshell: Data architecture integration and simplification
Databricks coined the term “lakehouse” in 2020, although their terminology can vary (Snowflake likes to talk about its data cloud, a hybrid of data warehouse and data lake). This data term has somehow broken the traditional real-world analogies to data terms (lakes, warehouses, marts, etc.).
A data lakehouse is a modern approach to data management that combines the scalability and flexibility of data lakes with the reliability and consistency of data warehouses. A data lakehouse allows companies to store large volumes of raw data while still being able to perform complex queries and analytics. It eliminates the need to maintain a data warehouse and data lake separately, leading to architecture simplification and reduced governance and, in turn, allowing organizations to unify data warehousing and AI use cases on a single platform.
A possibly better self-describing term also used, and which will possibly become the reference of new data platforms, is that of a unified data analytics platform (UDAP). While the lakehouse is a key component enabling the simplification of the data ecosystem, it is an end-to-end integrated data and analytics platform that aims to deliver a simplified approach to provide value of all your data to all the different data consumers. Soon, we will possibly see this term further evolve into an augmented unified data analytics platform (AUDAP or ADAP) as generative AI will be used to assist with data preparation, insight generation, and insight explanation. The recent announcement of Microsoft Fabric confirms the direction in which data platforms are evolving and puts Microsoft as possibly the first vendor in the AUDAP category.
Data team/organization structure: Centralized
Complexity of change: Medium to high. Depending on the amount of use cases to be moved to the data lakehouse, technical and organizational migration could lead to a considerable time and cost effort.
Why it’s the next choice: Consider a lakehouse as your “what’s next” choice if you:
-
Are currently doing data copies from data lake to data warehouse at scale and want to reduce data movement and data redundancy.
-
Struggle with data governance and want to create a single control point (unify data security and governance).
-
Need a single platform to ease the administrative burden and unify all data teams (data engineers, data scientists and analysts) on one architecture.
-
Want to unify data warehousing and AI use cases on a single platform.
-
Need to drive maximum value over the total cost of ownership (TCO).
-
Reduce time to data consumption.
Considerations and risks:
-
The benefits of a data lakehouse might not be realized by all your use cases. It’s important to evaluate and define benefits of moving to the lakehouse for your environment and assess which use cases should leverage this solution. It might be necessary for your organization to start with a hybrid solution (a combination of data lakehouse and data lake or data warehouse).
-
Evaluate the cost and effort of migrating from existing architecture to lakehouse architecture and value realization.
-
Some of the current solutions are still under development and, though they are progressing rapidly, it is recommended to test and evaluate.
-
Assess full TCO, including future costs of maintenance and development.
In our next article, we’ll tackle two other data management paradigms: data fabric or data as a service and data mesh or data as a product. If your enterprise are exploring a new way for managing data, Lingaro’s technology consulting practice provides end-to-end advisory and guidance on data management transformation.


