


Despite the popularity of data warehouses, enterprises investing in their development still confront challenges, especially in managing them as they grow and scale. As their users and use cases expand, data warehouses can pose problems as businesses try to keep up with the constantly increasing volume of information that comes in different types and multiple formats.
 |
 |
 |
|
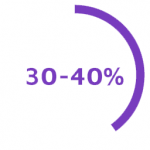
Between 30% and 40% of data stored by organizations is siloed in legacy systems and end up not being used for analytics. |
Moreover, 39% of all data within enterprises become idle and unused because of their high volume and the lack of capabilities to process it. |
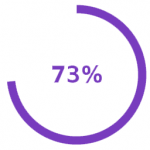
Ultimately, 73% of all data within enterprises goes unused for analytics. |
With these restrictions, we see a common trend among IT departments: migrating from on-premises Hadoop, data warehouses, and similar systems to cloud-based solutions and more functional data lakes. We also see IT teams building data lakes from scratch. Companies are trying to overcome problems with insufficient IT infrastructure by migrating solutions to the cloud. They’re also addressing problems associated with a growing amount of heterogeneous data by enriching the analytical ecosystem with data lake solutions.
These shifts pose a complication: Now that companies have moved to the cloud and data lakes, should they get rid of all their existing commodity data warehouse solutions?
Data lakes, which can store various kinds of raw data (structured and unstructured), were built initially with Apache Hadoop clusters on premises. Nowadays, they’re often based in the cloud. This way, companies can take advantage of their service-based flexibility, increased scalability, and better price-to-value coefficients. With these, companies aren’t forced to develop, organize, and maintain data lakes on their own.
However, businesses usually decide not to forego data warehouses. Instead, they create a symbiotic solution that links their old system to the new one.
So, to answer the question: No, enterprises don’t have to get rid of their existing data warehouse — it can be integrated with a data lake.
In this article, we’ll compare data warehouses and data lakes, and explore how companies can migrate to and merge old, on-premises data storage solutions with new cloud-based data lakes and move toward high-value data hubs.
Comparison of data warehouse vs data lake
On-premises data warehouses and cloud-based data lakes differ in that data warehouses store structured data and consist of relational databases while data lakes store both structured, unstructured, and semistructured data. Unstructured data includes images, videos, binary large objects (BLOBs), and data from internet-of-things (IoT) devices like wearables. JSON files are an example of semistructured data. Data lakes allow for broader and more flexible data exploration and are capable of analytical correlations across data points from various sources.
The constant influx of variously structured data is increasing in businesses, which, in turn, is fueling the demand for agile and flexible solutions for storing, analyzing, and reporting data. The cloud computing market always evolves: in 2022, IT spending for migrating to the cloud is pegged at over US $1.3 trillion. It’s projected to increase to US $1.8 trillion in 2025. These dynamics are affecting data management strategies.

Data lakes typically refer to a collection of data or a specific approach to data processing, not an independent data platform. Data lakes may be built with various enterprise platforms, such as relational database management systems, Hadoop, Google Cloud Platform, Azure Data Factory, and Azure Analysis Services. This is another significant difference between on-premises data warehouses and cloud-based data lakes.
Cloud-based data lake solutions uniquely detach the data storage functionality from data computation.
This can bring significant savings when it comes to storage and analysis of terabyte-size databases, since clients only pay for the computational power when they use it.
Expert insights
Snowflake has seen and helped many organizations looking to consolidate both their on-premises analytical databases (data warehouses abd data marts) and Hadoop data lakes and migrate them to the cloud. To exploit all of the potential value in their data, organizations are looking to centralize all data — regardless of structure — into a single cloud data lake capable of handling both schema-on-read and schema-on-write functionality, with flexible compute that scales to support multiple analytical applications. Snowflake’s unique cloud data platform addresses these requirements, whilst providing a familiar database API delivered as a low management SaaS service.
Simon Field
Field Chief Technology Officer for EMEA
Snowflake
The architecture of a data lake depends on different factors. The most crucial is the current data storage, processing, or management technology used in the company. For instance, some would use SQL databases, with SQL-based data exploration and extract, load, and transform (ELT) pushdown. They may require the implementation of a relational data lake with relational database tools. Others would use Hadoop as their preferred platform for data lakes as it’s capable of linear scaling and supports various analytics techniques. It also might cost less than similar relational configurations. Some find data lakes implemented in a cloud service to be the most flexible, scalable, and agile.
The data lake approach is much more flexible than the traditional data warehouse infrastructure as it doesn’t require excessive preprocessing, cleaning, transformation, or other types of preparation. Data may be stored and provided for analyses in a raw and original state, or it could come directly from the source. The dataset cluster can then be activated and analyzed according to the future demand. It doesn’t require to be active at all times like traditional data storage solutions. This can substantially lower data maintenance costs. At the same time, old functionalities are retained, as
data stored in data lakes can be easily loaded into data warehouses or data marts, or directly consumed by analytics and business intelligence software and tools.
Expert insights
It’s worth mentioning that when it comes to building analytics solutions in the cloud, “either-or” strategies don’t work best for data lakes or data warehouses. A data lake is one part of modern data architecture that allows more solutions to be built flexibly in the future.
Let’s take Azure Synapse Analytics as an example of a platform which combines a traditional SQL-like approach with modern Spark-driven architecture. Integrated analytics runtimes offer provisioned and serverless on-demand SQL Analytics offering T-SQL for batch, streaming, and interactive processing. At the same time, Spark runtime can be used for big data processing jobs with Python, Scala, R, and .NET.
What’s the key element of such an approach? Both runtimes are data lake-integrated and Common Data Model-aware. In case you are curious, the Common Data Model brings semantic consistency to data within the data lake. When data is stored in this form, applications and services can interoperate more easily.
Bartłomiej Graczyk
Senior Cloud Solution Architect
Microsoft
Data lakes can support multiple functions and interfaces. A growing trend is to use a single data lake as a new and better area for data landing and staging, and also to use it in an exploratory and discovery-oriented way (the so-called analytics sandboxes) to find some new and interesting data correlations. As the data lake approach doesn’t impose the structure on the data, it allows new datasets to be added on the fly.
From a business perspective, Lingaro’s data lake implementation delivers these benefits:
 |
 |
|
From a technological context, these benefits mean:
|
Data Lakes are not a revolution as much as they are an evolution of the existing technologies. They comprise multiple types of data systems and allow the development of hybrid data ecosystems that are suitable to use cases like multichannel marketing or analysis.
In the following table, you’ll find a brief comparison of on-premises data warehouses and cloud-based data lakes:
|
On-Premises Data Warehouse |
Cloud-Based Data Lake |
|---|---|
|
Relational data |
Diverse types of data |
|
Storage combined with computation |
Storage detached from computation |
|
Comprises a majority of refined calculated data |
Comprises a majority of detailed source data |
|
Entities and dependencies are known and tracked over time |
Entities are discovered from raw data |
|
Data must be integrated and transformed upfront |
Data preparation on demand |
|
Usually schema on write |
Usually schema on read |
|
Limited scalability |
Scalability more adjustable |
|
Integration with third-party software requires data transformation |
Easy integration with third-party software |
Migration from on-premises data warehouses to cloud data lakes
Replatforming is a typical strategy for companies with data warehouses deployed on their premises. Businesses are increasingly moving their databases to the cloud, but upgrading or migrating a data warehouse requires a plan that takes into account the time span, risks and costs, potential business disruptions, and its overall complexity. Not only is data moved to the new platform — its management and users do, too. Many data warehouse migration projects end up taking care of uncontrolled data marts or simplifying the vast number of databases by consolidating them into fewer platforms.
Cloud-based data lakes can address consolidation as they’re globally available platforms and can be easily centralized.
The ideal approach to implementation is to start small, preferably with a minimum viable product (MVP). Start with a low-risk, high-value segment of work that divide jobs into manageable segments, each with a technical goal and a purpose for adding business value. Starting with a bloated project can be quickly overwhelming, what with its size and complexity. A multiphase project plan can help deal with incoming challenges. Focusing on a segmented dataset that’s easily constructible and demanded by the business is often the best way to begin the data migration process. It will give others within the company a sense of urgency and confidence to proceed to more complex data subsets.
Expert insights
A data warehouse and a data lake complement each other. They do not compete directly, and one does not replace the other. Any real enterprise solution has a bit of both to some extent.
A number of ETL processes need to be revisited and maybe become ELT to leverage the performance of the data lake for processing. Aggregates from the data lake are fed into the data warehouse with analytics cutting across the entire data flow.
Emmanuel G. Ngala
Technology Solutions Engineer
Oracle
Organizations might stumble upon failures in the migration process, so contingencies should be planned for risky milestones. Automatic testing and scripting for systems should be developed to increase quality and avoid migration problems. During the migration process, the data warehouse and data lake will function simultaneously, at least in some of their crucial parts. The duration of this process depends on the complexity and size of the databases, user groups, and processes.
Migration does not only mean moving and consolidating system elements. It might require further development, especially if there are many uncontrolled processes in the databases. The “lift-and-shift” strategy is sometimes possible, but at other times, organizations might be forced to develop data models and interfaces to maximize performance on the cloud platform. The lack of backward compatibility might force teams to develop some specific components and routines, like stored procedures and user-defined functions. Additionally, the quality of data and previous data models could influence the new platform. Cloud solutions are not a magic wand, so try not to migrate old problems with the old platform.
Data migration doesn’t require only architecture and data modeling experts. Data maintenance workers, such as database administrators and system analysts, are also necessary. Moreover, the migration will affect many elements and departments in the company — from data modeling and analysis, reporting, dashboards, and metrics to business intelligence, to name a few. Each of these elements might be generated or supported by a different business branch.
Migration to the cloud could be an opportunity to improve the quality of data that was previously generated in various departments of the company.
Consider if only the IT team and managers should be involved in planning the modernization of the data warehouse, as other departments and end users can also provide significant insights.


