


As stated in our previous articles, we can observe a recent increase in the implementation of Data Lakes. Even though all sorts of Data Warehouses (DWs), on-premise and in clouds, are still the main data storing technologies; more technologically advanced companies are aiming to switch to optimal and faster technologies, which become cheaper in the long run.
Moreover, the latest cutting-edge approaches to data are not even Data Lakes, but Data Hubs. As Google’s Trends analysis shows, recent years have brought an overwhelming increase in Data Lakes and Data Hubs search queries, while the interest in DWs is steadily declining (Fig. 1). Understandably, the search interests go in accordance with the business hunt for more optimal data storing and analysis services.
.jpg?width=982&height=366&name=22-(Compressify.io).jpg)
Figure 1. Data Hub, Data Lake, and Data Warehouse as terms that were searched for over the last 15 years. DWs web search is slowly falling, while searches for Data Hubs and DLs are increasing.
.jpg?width=1015&height=381&name=11-(Compressify.io).jpg)
In this article, we will describe Data Hubs and compare them to other solutions, like Data Lakes and Data Warehouses. Still, it should be emphasized that all the solutions presented below can be implemented together, in one business. They are complementary approaches, rather than competing ones.
In the following sections, we will compare various methods of storing and managing data:
-
Database core architecture patterns and the novelty of Data Hubs
-
Why Data Warehouses and Data Lakes are not enough?
-
Data Warehouses, Data Lakes, and Data Hubs – the differences and similarities
-
Data Hub data flows
Database core architecture patterns and the novelty of Data Hubs
Data Hubs are elastic data harmonization and storage services, that are capable of combining data sets not only from various devices, company departments, and data types (like Data Lakes do), but they can also integrate data from a couple of different companies.
Essentially, Data Hubs are data integration services that allow to (physically) move and re-index your data into a new system.
Therefore, Data Hubs have indexing, discovery, and analytics functionalities.
In conventional systems, data is stored in silos or in warehouses. These can quickly become the bottlenecks of your company’s IT system, if they store fragmented or incompatible data. In Gartner’s study, more than 50% of old data integration solutions based on Data Warehouses fail; and the bigger the spread of data across various systems and sources, the harder companies fail. Moreover, storing data in many different systems may worsen the situation. In these cases, such systems not only slow your work down, but they may also suppress innovation. The integration of disparate data is difficult and needs advanced tools, skills, and requirement fulfillment, like BRS, SRS, Performance Stress test (PST), Technical Acceptance Testing (TAT) etc. This is where DH may work at their best, in progressive data harmonization.
Some IT specialists attempt to work around the problem of data integration and apply an old approach: parallel adoption or big bang adoption. They develop a new, global data model that includes all kinds of data types from various company departments, from all the data silos. A new Data Warehouse is created by using ETL and by mapping every silo to the new model, checking the data structure and data interdependencies on the way. This is not an optimal solution. As the above-mentioned Gartner study has shown, it can be slow and time-consuming, and therefore more costly. In turn, progressive harmonization of data used in Data Hubs avoids the parallel or big bang adoption by modelling just the necessary parts of a global system when they are needed. This way a data service is created which can be encapsulated in an agile and phased approach. As a result, more data output can be added later to the existing core of the harmonized data.
Why Data Warehouses and Data Lakes are not enough?
Data Warehouses and Master Data Management were both the long-awaited responses to the “data silo crisis” of the 1990s. In turn, the last years were the advent of Big Data, Machine Learning, NoSQL, and ultimately Data Lakes. This trend has dealt with some DWs drawbacks, like the limits of legacy or data type restrictions. Unfortunately, data silos problems have never been entirely solved. When DWs were in rein, data integration was approached by the development of a single model fitting all data shared across the company. ETL was the method used to load data into the model, making DWs quite static, slow, and limited in scalability and agility.
Data Lakes brought improvement of the DW architecture, by adding the functionality that helped with storage and analysis of both structured and unstructured data. Data Lakes are also faster than DWs by design, making them better tools for data scientists, data managers, and other decision-makers. Storing significant amounts of data and fast processing come with a price though.
Data Lakes may suffer from certain technological defects, like problems with security, data governance, and Data Swamps. If a Data Lake is set up on Hadoop, it may additionally bring the problem of limited speed. In most contemporary uses of Data Lakes, they are a technology used complementarily with DWs, and it is important to keep them in the loop, not as disconnected databases, since in such cases they would comprise just another data silo.
Today, the big topics in data analysis are real-time data analysis on the fly, data management agility, and data harmonization. Data Lakes are indeed decent solutions when it comes to scalability and support for various data types. But because of this reason, they lack the harmonization functionality, without creating space-consuming copies of data. There are data catalogs available for Data Lakes, but they still have problems with the speed of data searches. Data Hubs were invented to satisfy exactly these needs.
Currently, developers are focusing on additional functionalities in this novel architecture – namely, adding support and increasing compatibility with BI software, machine learning, and other AI algorithms etc. Furthermore, DH, like DL, can have support for acquiring data from many sources through, for example, replication, which uses changed data, capture functionality to populate the Data Hub in real time. Another database population strategy could be the publish-and-subscribe interface, which subscribes the hub to messages published by constantly changing data sources.
Therefore, an optimal Data Hub is not just another data silo or repository. Besides data storage, it should have the functionalities of data harmonization, indexing, governance, query, discovery, and analysis (Fig. 2).
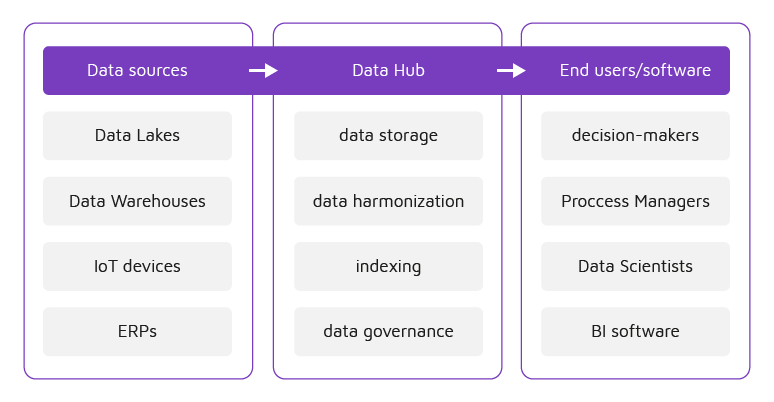
Figure 2. Data sources for Data Hubs, their functionality, and their output end-users.
Data Hubs are also increasingly used for efficient complex business management. They can integrate information and data from different sources coming from a group of companies at the same time. This solution is called a groupware service. The service is supposed to increase group cooperation and synergy due to the improvement of business processing capacity, and thereby reducing operational costs.
Such systems are especially useful to handle format differences of various data sources, harmonize the data, and as a result, control the already mentioned data heterogeneity problem. This is an even more interesting solution, since it operates the Data Hub on the cloud, not on-premise, and so it additionally increases the strategy agility.
Data Warehouse, Data Lake and Data Hub – the differences and similarities
After discussing all the similarities and differences of various data approaches, we have created a summary in the form of the chart below.
Data Warehouse — Data Lake — Data Hub
| Data storage | Yes | Yes | Yes |
| Data placement | In a silo | Many silos in one place | Many silos in one place |
| Indexing | Yes | No | Yes |
| Harmonization of data | Yes | Very little to none (incompatible data formats) | Data is indexed in a harmonized form |
| Data latency | Bigger | Smaller | Smaller |
| All types of data | No | Yes | Yes |
| Inherent analytics | No | Yes | Yes |
| Optimized for machine learning | No | No | Yes |
Data Hub data flows
To sum up, Data Hubs are slowly becoming the new trend in business data storage and processing. They are a natural step forward, improving the previous solutions – Data Lakes and Data Warehouses. At the same time, Data Hubs are not supposed to eliminate Data Lakes and DWs. On the contrary, they can make a useful, complementary service. Data Hubs improve the quality of data, its latency, and also reduce the business unit dependency on IT for new reports and insights and eliminate the need to transform the existing DWs.


