


Data Fabric as a revolution, not an evolution.
People tend to simplify things. Instead of saying: a company with a robust data analytics platform, assembled from multiple systems; we would rather put it as a “Data Warehouse” or “Data Lake”. Here the name stands for the general idea or approach, rather than fora specific part of the whole data platform. Let’s move on and take a closer look at the concept of Data Fabric.
Brief summary of reporting and analytics history
To begin with, let us quickly review the history of reporting and analytics. Long ago, engineers realized that reporting activities cannot occur on the applications’ production databases, because this slowed them down. So, the solution of replicas came into action. As the amount of different applications increased, it became clear that businesses could improve their results by combining insights from different independent systems.
That is how we ended up with Data Warehouses. Since everything moved forward, the variety of data sources increased and it was no longer possible to adjust all of them into DWH. Sounds familiar? From here we moved onto Data Lakes. Does this mean that all our data expectations have been met? Not at all. We live in a world that is changing incredibly fast. This is why we constantly strive for systems that will allow us to operate on new ideas and initiatives faster than our competitors.
From Data Warehouses and Data Lakes to the Data Fabric Concept
A well-known way to get results faster is to automate processes at some level. Let’s go back to the DLs and DWHs. If you wanted to bring new sources into a DWH, you had to go through long modeling processes to obtain any results. Certainly, Data Lakes have improved the pace of delivery. But is this the limit of our capabilities?
Absolutely not. Both DL and DWH approaches are about moving data physically from one place to another, where we have both storage and computing power to manage it all. For an enterprise, this could be a problem, as the data is often widely distributed between different geographical locations. Now, let us take a closer look at the idea of Data Fabric.
.jpg?width=1024&height=681&name=shutterstock_530826679-1024x681-1-(Compressify.io).jpg)
What is Data Fabric and how it fits into enterprise data environments
First of all, we need to keep in mind that this new approach is applied to the whole data ecosystem. In order to understand it conceptually, it is best to think of fabric that stretches across all the data, regardless of its location being on-premises or in the cloud. In simple terms, Data Fabric is a distributed data environment that connects all data together, so that it can be seamlessly accessed by data management services and utilized by end-users, or by applications. You shouldn’t think of it as a specific solution, but rather as a whole approach or way of accessing data seamlessly.
Data Fabric is not a single service but an entire ecosystem that may be developed regardless of the existing data sources or infrastructure types. Data is not physically moved in order to create a “single source of truth”.
The principles and main challenges of Data Fabric
So far everything about Data Fabric sounds great, but every solution has its pitfalls and tricky areas. Here are the main principles and challenges which should be kept in mind:
Data Volume & Performance
-
The Data Fabric must be capable of scaling both in and out, regardless of the overall increases in data volume.
-
Performance is 100% the ecosystem’s responsibility, so the data access can focus solely on the business goals.
Accessibility
-
The Data Fabric has to support all access ways, data sources, and data types by design.
-
It offers multitenancy; so different users may move around the fabric without impacting others, and the same goes for heavy workloads, so they don’t consume all the resources.
-
Knowledge of underlying source systems is not required since the logical access layer enables consuming the data regardless of how or where it is stored or distributed.
-
Supports combining both data at rest and data in motion.
Distribution
-
The Data Fabric needs to stretch across different geographical on-premise locations, cloud providers, SaaS applications or edge locations, with centralized management.
-
Transactional integrity of the fabric is required, so to govern all the processes successfully it needs a wise master data replication strategy. Later, it is used to deliver consistent results from multi-location queries.
Security
-
The logical access layer brings another level of security, which can be managed from any single point.
-
The Data Fabric can allow passthrough of users’ credentials to the source systems so that access rights are evaluated properly.
Data Fabric high-level design
The most important fact in the Data Fabric’s HLD ecosystem, is that it is a rather distributed platform than an end-to-end reporting or data management system. The diagram below illustrates the changes in comparison to well-known solutions.
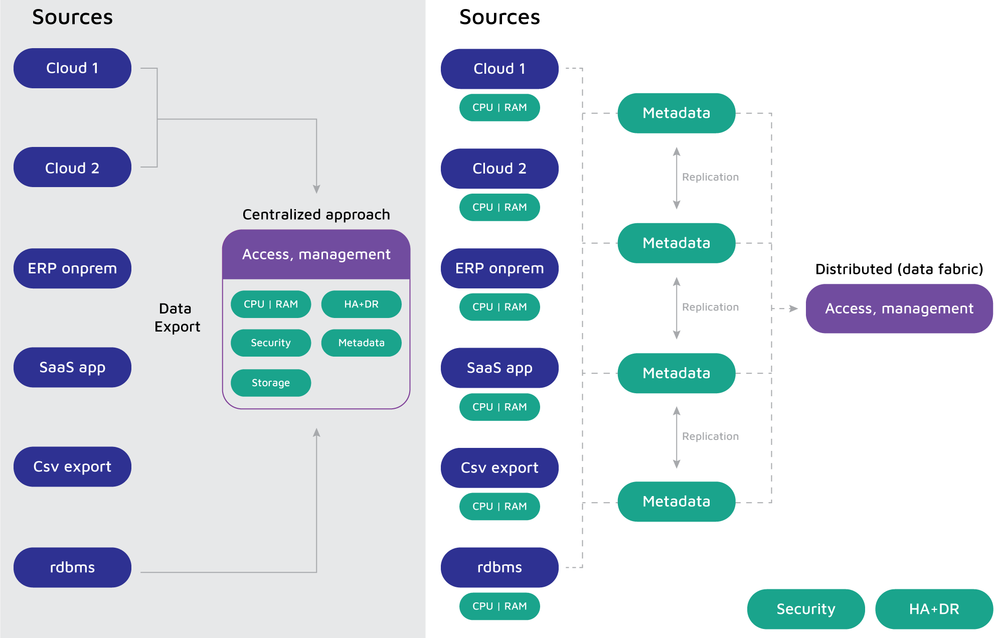
Data Fabric as the new data management platform: Why you need it
Nowadays, companies are becoming overwhelmed with either the number of data sources or by the complexity of unifying them. In order to find a solution that treats the causes and not just the symptoms, we need a significant change in the paradigm of data exploration. Instead of following the never-ending pursuit for meeting the SLAs in more and more complicated ETL/ELTs, maybe we should assign the responsibility for the speed, agility, and data unification to the Data Fabric platform. The entire ecosystem should incorporate new sources and enable them to cooperate with others by its very design. This would help with most of the analytics solutions’ problems with performance, scalability, and the integration of new data types.
As stated in our article on Data Warehouses and Data Lakes, neither should exist alone. Each solution is best suited for different scenarios, and so decisions should be made after careful consideration and with the appropriate knowledge. Nevertheless, together DWHs and DLs overcome most of the problems that clients currently experience. They always work by taking data from one place, transforming it, putting into another location, and so on. Data Fabric, on the other hand, does not consider permanent data movement. It leaves the data as it is, in the sources. This way we can avoid further problems like:
-
Dependencies in multiple flows; waiting for some data to be processed before moving forward, which leads to increased latency.
-
Lack of atomicity; whenever entangled flows were experienced in a middle step failure, this wasn’t an easy job to clean up and re-run only the failed ones.
-
Latency in the delivery of new data sources to the reports, due to the design of the ETL/ELT process.
Conclusion
Every day we see companies developing faster and faster with a constant increase in the pace of innovation. This drives the rotation of new software and applications and has an impact on data management and analytics solutions, as businesses that operate at the top level must be data-driven. Approaches that have been used for years in data management and analytics might find it difficult to keep up with the pace. We will probably have to redesign the way we think about this area. Data Fabric’s design and core principles resolve the majority of the current and most serious problems encountered in developing and using DLs and DWHs.
By leveraging the cloud platform possibilities, we can finally build a solution with unlimited scale and power. This makes the idea of Data Fabric real and presents it as the most promising approach to the data management of the future.




