


Previously, we have been writing about “The co-existence of Data Lakes and traditional DW ecosystems” and “Data Lake Unique Implementation Approach”, thereby effectively discussing DL architectures and their implementations.
In this article, we are going to describe in detail the possible threats and challenges that both, beginners and more advanced developers of Data Lakes may encounter. How to proceed to create a successful Data Lake without e.g., falling into Data Swamp?
Our recommendations on Data Governance, Security, and Structure. How to improve them in your Data Lake? Our answers to the following challenges will provide tips, that might be useful while working with Data Lakes.
1. You have built a system, where your data is heterogenous and isolated. How can Data Lakes avoid siloed data?
Obviously, it is difficult if your data is siloed at a specific location. You may attempt to create a refined Data Warehouse, but the integration of all your data may be very time and resource consuming. Cloud Data Lakes mitigate these problems, while not requiring to form the final data structure. If you wish to further reduce time and effort for additional data set integration, you may use a metadata driven framework.
This means you automatically scrape the tags and labels of your databases, spread all over your business departments, and make them quickly and easily accessible.
Data Lakes do not require you to collect all data in one physical location, so they eliminate one of the biggest setbacks of DWs when it comes to large volumes of data.
Data Democratization is also useful when preventing data isolation. Authorized users can access the data without any restrictions. The Data Lake approach allows you to manage the data from a single point, centralizing various data formats and types, and making it available to all authorized stakeholders.
As we have written in the previous article, the next natural step after implementing Data Lakes is a Data Hub. Data Hubs and well-developed Data Lakes allow you to integrate data by using the “Schema on Read” operation. This means that you preserve your old way of storing raw data, but you load and integrate only those pieces that are common for many cases. This “lazy integration” methodology makes it possible to register the chosen files on the fly, when you read them in a specified way. The control over reading is preserved by using pre-defined data schemes.
Additionally, we recommend working on multi-layer frameworks. This way, you can aim at reusing your low-level components, and will not need to develop as much code, rather you would go for configuring an existing code instead. This will significantly reduce development costs. You may implement a lot of functionalities in a Data Lake that are difficult to develop from scratch for individual cases (advanced monitoring, management, CICD, automated data quality validation, advanced profiling and tuning, auto documentation etc.).
2. Data Warehouses are structured but inflexible. Over time, don’t Data Lakes become as complex as Data Warehouses?
As we know, Data Warehouses are data repositories for filtered and structured data, that has been already preprocessed; while Data Lakes are pools of raw data. Data Warehouses are not as flexible; you need to consider the various business procedures existing in your company, while building them, and later restructure them if necessary. This obviously increases rework, e.g., with regards to regression and non-negative impact testing. Dealing with DWs becomes more complex, since many datasets and issues are interconnected with this structure.
DLs are more flexible than DWs and do not require prediction of each and every business detail while building it. You can first collect data, regardless of any structure, unless you intend to endow structure to the data from the very beginning. Of course, sometimes that’s exactly what you want to do, if some part of your database is common and reusable across various business functions.
Moreover, since DLs store all unprocessed data in the same place, you can access and extract it easily, receiving additional information. Based on that, you may build more structures on such data, in order to answer some particular business requirements. The Data Lake you build may be covered later with a new reporting layer, e.g. a specialized Data Hub, dedicated to a specific business unit.
Overall, the Data Lake architecture is a solution that decomposes a series of business problems into a manageable list of separate challenges. You are better equipped to efficiently deal with these challenges individually. In the previous answer we have recommended creating technical multi-frameworks, because once you create them, you are able to reuse them in the next iterations of your system. This will allow you to focus on the business aspects, rather than on development issues.

3. Building a semantic layer and getting rid of SAP BW BEx.
First of all, we recommend employing two additional services to your Data Lake framework: data catalogue and data lineage. Data catalogues allow for discovery, management, and dispersed data (data coming from different sources) understanding. They may catalogue not only technical, but also business data, and thanks to the centralization of Data Lakes, they can be retrieved from one place. BEx can therefore be made obsolete, by integrating the optimized DL with the reporting tools and by building a proper semantic layer.
4. Final data and process roadmaps. How specific should they be when starting to work with Data Lakes?
In terms of solution design, you should have a detailed plan for your system architecture. You should decide on the technologies used in your Data Lake, the connections between them, high-level data flow, and define your data strategy/approach, and framework. This is necessary to determine support on a global level and what should be defined per application, business, or region etc. If your system also involves a Data Hub, then you should specify the split rules between your DL and DH.
On the other hand, you do not need to specify the data transformation and integration details in DL solutions. Whereas in the Data Warehouse approach, you have to do that.
5. Finding the data source for my Data Lake. SAP ECC or the already preprocessed SAP BW?
In principle, Data Lakes were devised to store raw, unprocessed data. However, in some situations your business logic does not allow you to easily understand the data and move it to the cloud. Such situations may take place, for example when the previous development team ceased to exist. In such circumstances, you may as well move the data and treat it as raw, with a stipulation that this data lineage is probably untraceable.

6. Data loading destination in the newly created Data Lake. Should you load data into the Landing Zone?
You may choose one of the two possible architecture solutions, and based on that you will define the location of your loaded data.
You can move aggregated data to a landing zone and treat it as raw data. This solution is faster and cheaper to develop, but it comes with additional maintenance costs. Moreover, using this solution you will most probably lose the ability to check the correct lineage of this type of data, and the transformation logic will be maintained outside the Data Lake.
The other option is aggregating the raw data after you have imported it to the Cloud Data Lake. The obvious advantage of this move is the logic preserved and stored in one place, the correctness of the data lineage, and the increased speed due to the scalability of the cloud solution. The disadvantage of this strategy is an increase in initial costs and efforts to develop this at the beginning.
7. Loading huge amounts of data at once creates a threat of duplicates.
The Data Lake’s landing zone will probably contain duplicates, since it is intended to collect all kinds of data, from various sources. The data is most likely already duplicated in your overall system. If you wish to treat your Data Lake as the ultimate source of truth, you need to develop a logic to remove the duplicates from your final system.
8. Making your Data Lake co-exist with SAP BW.
There are architectures that makes this possible. We may call the first one “Architecture with warm/hot data”, you can cut the costs by keeping the hot data in SAP BW and the cold data in the Data Lake (Fig. 1).
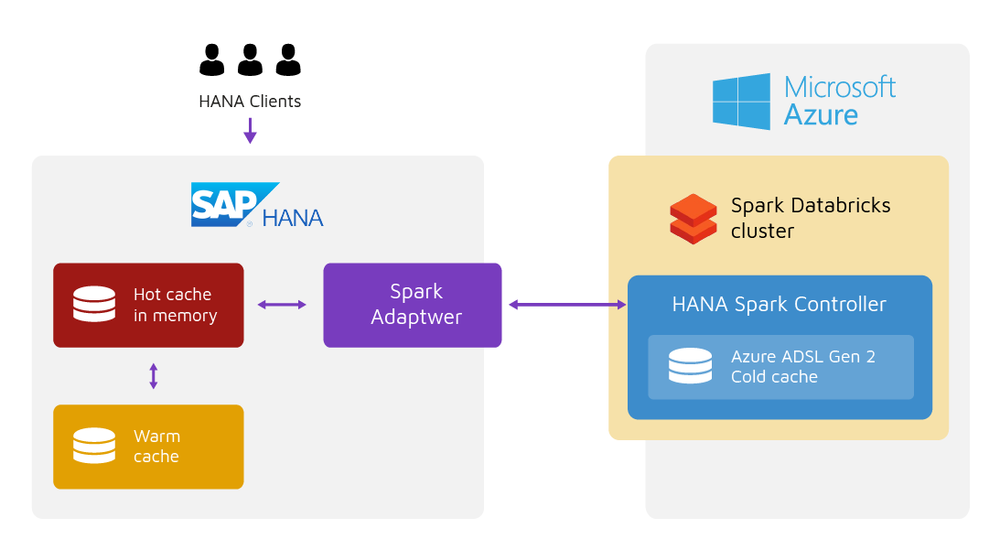
Figure 1. Architecture where you keep hot data in SAP BW and cold data in a Data Lake.
The second architecture would be “compute architecture”, where you move data from SAP BW to the Cloud Data Lake for scaling and processing. This solution also cuts costs, and additionally increases speed.
The third possible architecture is the decentralization of the endpoint for retrieving data. Here the data from SAP BW on-premise would be replicated. This way, the reporting tools would not be necessarily pointing to SAP BW anymore, but we would have a new repository for additional services.
In summary, Data Lakes can bring benefits even if you have already invested in SAP BW. Cloud Data Lakes make it easier to join preprocessed and standardized data coming from different business units in your company, together with unprocessed, and unstructured data. Moreover, Data Lakes improve disaster recovery, making the data more resilient. Data Lakes are more scalable (Scale Out) and more open to further development (e.g. to Data Marts, Data Hubs etc.) as they are more platform independent.


