

.jpg?width=750&height=240&name=Blog-cover-Data-Warehouse_%20Data%20Lakes-1-1-(Compressify.io).jpg)
Organizations typically build data warehouses as a central place to store internal data assets from across different business functions. However, the increased diversity in use cases for analytics created a shift in the industry where alternative design patterns, such as data lakes, became widespread. However, our experience working with Fortune 500 companies and global brands indicated that while these new design patterns accommodated specific use cases, the data warehouse — and the key benefits and ROI it offers — are still a mainstay in their data and analytics strategy.
Data warehouses are a business norm. In 2020, 57% of data and analytics leaders invested in data warehouses to support their multifaceted data workloads. The pandemic — and the compelled need to digitally transform — sped up their adoption: 89% of surveyed companies now maintain either an on-premises or cloud-based data warehouse, and organizations are increasing their investment to improve or modernize their capabilities in analytics and accelerate their journey to the cloud.
What is a data warehouse?
A data warehouse usually stores current and historical data derived from transaction data in a single place that is used for creating analytical reports. The data warehouse is the core of the business intelligence (BI) system, which is the decision support database maintained separately from the organization’s operational database.
Data warehouses and data lakes are not interchangeable and are not direct replacements of each other. They both deal with the collection and management of data from various or multiple sources, and their use cases might overlap in some situations, but they differ in many features, such as the structure of data they are storing or processing, their key end users, accessibility, complexity, and the tools and technologies required for setup and deployment.
Data warehouse architectures
There are several implementation methods, the most notable of which are:
-
The traditional bottom-up approach introduced by Ralph Kimball.
-
The corporate top-down approach proposed by Bill Inmon.
-
The Agile Data Vault 2.0 methodology devised by Dan Linstedt.
-
Newer solutions that address the increasing volume of data and capabilities of cloud platforms, such as a modern cloud data warehouse or a data lakehouse.
.jpg?width=1024&height=358&name=Diagrams-Redo-2-1024x358-(Compressify.io).jpg)
.jpg?width=1024&height=325&name=Diagrams-Redo-3-1024x325-(Compressify.io).jpg)
Figure 1. Visualizations that compare the data warehouse architecture design of Kimball (top) with Inmon (bottom)
Factors to consider when building the data warehouse’s architecture
Designing the data warehouse’s architecture can be complex, dynamic, and lengthy, which also depends on business functions and use cases that change over time. Factor in these essentials before deciding on what approach to use for building the architecture:
-
Reporting needs
-
Volume and quality of data
-
Frequency of changes
-
Inflow of new data sources
-
Deadlines and timelines
-
Access to knowledge base
Implementation options to data warehouses
A data warehouse can be implemented in three fundamentally different ways: on-premises, cloud-based, and hybrid. Each approach might share a common set of tasks, such as analyzing business requirements and designing the architecture, but they have their own scope, features, associated costs, and business use cases as well as pros and cons.
Implementing a cloud-based data warehouse is now more common, as it takes advantage of the cloud’s performance, capacity, on-demand elasticity, and cost-effectiveness. Of course, a cloud data warehouse also has its challenges, such as latency issues and reliance on internet.
An on-premises data warehouse, on the other hand, provides more control, centralizes governance, and alleviates latency issues (if sized and scaled properly. And while an on-premises data warehouse gives full control, it equally provides total responsibility.
The hybrid model, which combines the features of an on-premises and cloud-based data warehouse, can be a good alternative if their drawbacks outweigh the benefits for the organization. It’s not without downsides, however. Implementation and maintenance are more complex, and integration of data between private and public cloud can be complicated.
Bridging silos with a logical data warehouse
A relatively recent approach to data warehousing is the logical data warehouse (LDW). LDWs combine various design patterns into single coherent architecture. The “traditional” data warehouse, like an on-premises data warehouse, is a key component of this architecture. LDWs can also include data lakes and data marts (data warehouses specific to a single subject or line of business) as complementary engines. Using them makes the data warehouse easier to design.
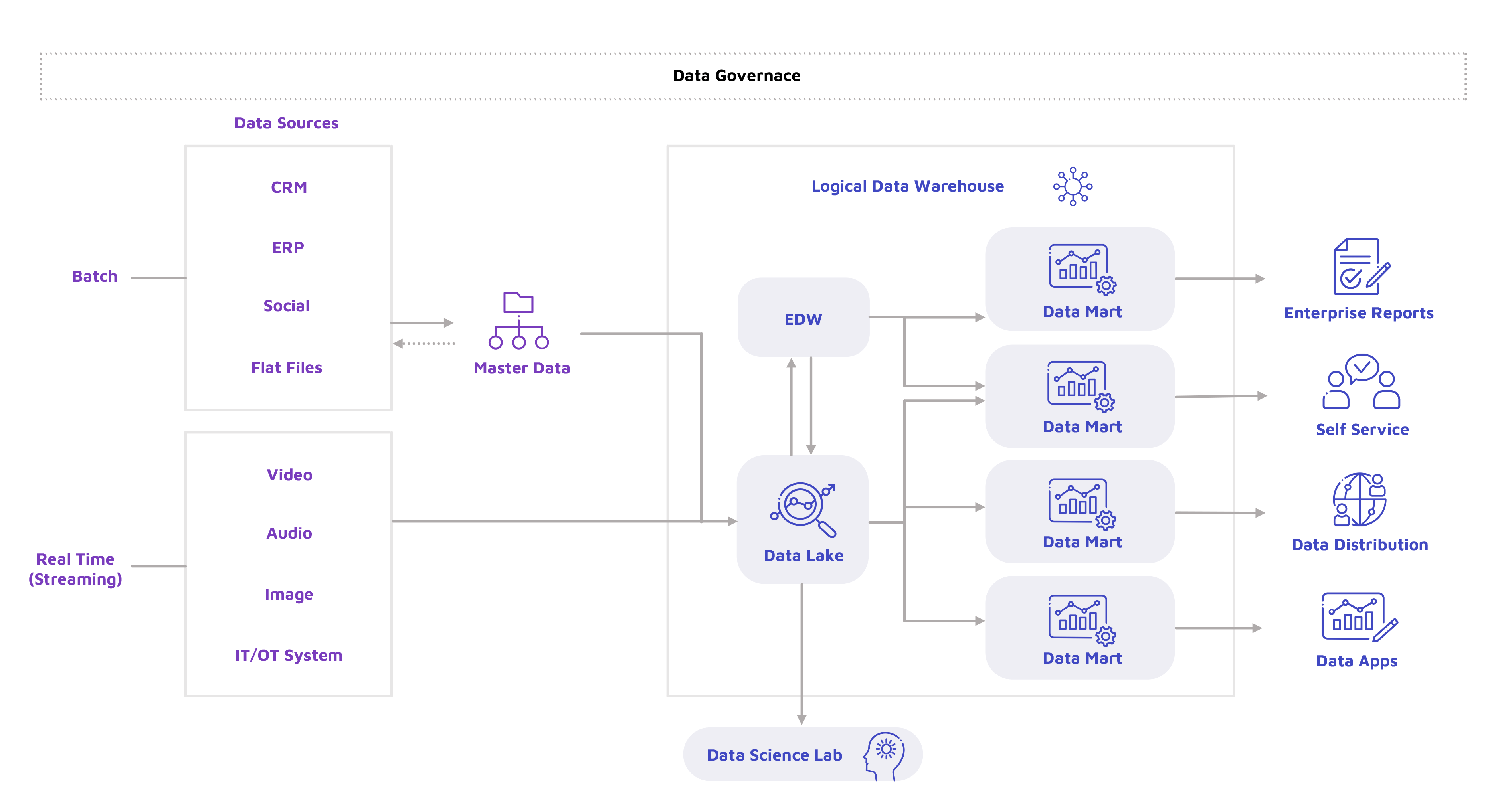
Figure 2. A diagram visualizing the different components of a logical data warehouse
Indeed, data warehouses remain a key element in data and analytics platforms and provide a consistent view of enterprise data. They act as a catalyst in the organization’s efforts toward data governance and serve as building blocks for the company’s business intelligence and decision-making.
There are many elements to building an efficient and effective data warehouse beyond serving accurate and timely information. Download our full guide, “The Data Warehouse: A Guide on Building the Business’s Catalyst for Analytics,” which provides an overview of the data warehouse, the notable architectures and deployment approaches that organizations can consider implementing, and some industry best practices for building or expanding a data warehouse.




