


Data Lakes Architecture are storage repositories for large volumes of data. Certainly, one of the greatest features of this solution is the fact that you can store all your data in native format within it.
For instance, you might be interested in the ingestion of:
-
Operational data (sales, finances, inventory)
-
Auto-generated data (IoT devices, logs)
-
Human-generated data (social media posts, emails, web content) either coming from inside, or from outside the organization.
Layering
We may think of Data Lakes as single repositories. However, we have the flexibility to divide them into separate layers. From our experience, we can distinguish 3-5 layers that can be applied to most cases.
These layers are:
-
Raw
-
Standardized
-
Cleansed
-
Application
-
Sandbox
However, Standardized and Sanbox are considered to be optional for most implementations. Let’s dive into the details to help you understand their purpose.
-
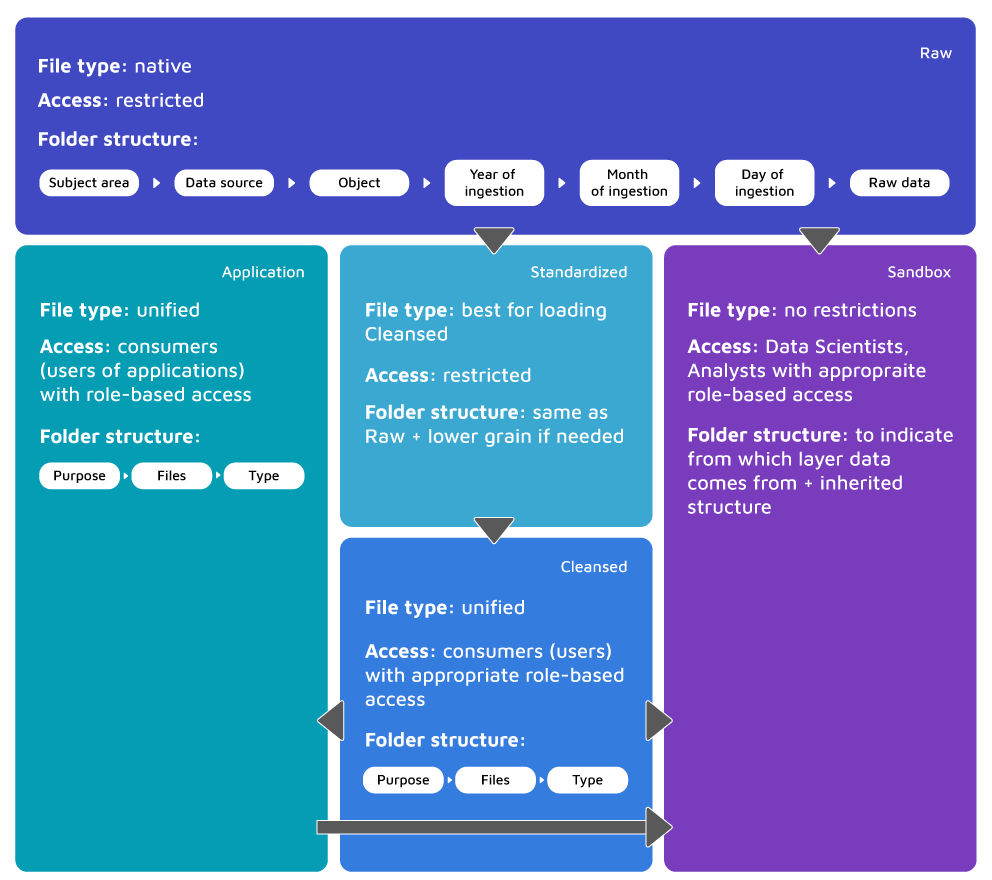
Raw data layer – also called the Ingestion Layer/Landing Area, because it is literally the sink of our Data Lake. The main objective is to ingest data into Raw as quickly and as efficiently as possible. To do so, data should remain in its native format. We don’t allow any transformations at this stage. With Raw, we can get back to a point in time, since the archive is maintained. No overriding is allowed, which means handling duplicates and different versions of the same data. Despite allowing the above, Raw still needs to be organized into folders. From our experience we advise customers to start with generic division: subject area/data source/object/year/month/day of ingestion/raw data. It is important to mention that end users shouldn’t be granted access to this layer. The data here is not ready to be used, it requires a lot of knowledge in terms of appropriate and relevant consumption. Raw is quite similar to the well-known DWH staging.
-
Standardized data layer – may be considered as optional in most implementations. If we anticipate that our Data Lake Architecture will grow fast, this is the right direction. The main objective of this layer is to improve performance in data transfer from Raw to Curated. Both daily transformations and on-demand loads are included. While in Raw, data is stored in its native format, in Standardized we choose the format that fits best for cleansing. The structure is the same as in the previous layer but it may be partitioned to lower grain if needed.
-
Cleansed data layer – also called Curated Layer/Conformed Layer. Data is transformed into consumable data sets and it may be stored in files or tables. The purpose of the data, as well as its structure at this stage is already known. You should expect cleansing and transformations before this layer. Also, denormalization and consolidation of different objects is common. Due to all of the above, this is the most complex part of the whole Data Lake solution. In regards to organizing your data, the structure is quite simple and straightforward. For example: Purpose/Type/Files. Usually, end users are granted access only to this layer.
-
Application data layer – also called the Trusted Layer/Secure Layer/Production Layer, sourced from Cleansed and enforced with any needed business logic. These might be surrogate keys shared among the application, row level security or anything else that is specific to the application consuming this layer. If any of your applications use machine learning models that are calculated on your Data Lake, you will also get them from here. The structure of the data will remain the same, as in Cleansed.
-
Sandbox data layer – another layer that might be considered optional, is meant for advanced analysts’ and data scientists’ work. Here they can carry out their experiments when looking for patterns or correlations. Whenever you have an idea to enrich your data with any source from the Internet, Sandbox is the proper place for this.
While data flows through the Lake, you may think of it as a next step of logical data processing.
Data Lake Architecture: Important Components
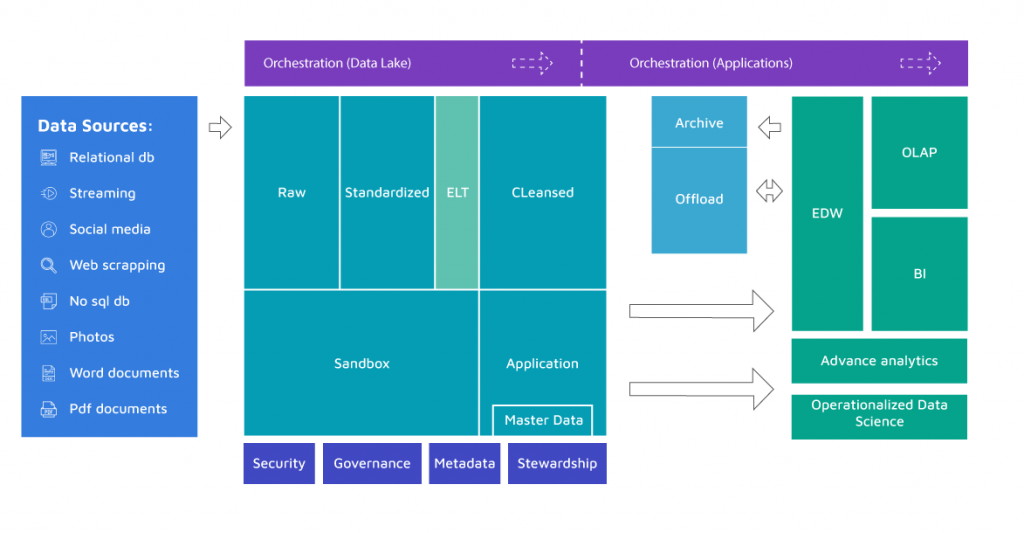
Since we have covered the most vital parts of Data Lakes, its layers; we may now move on to the other logical components that create our solution. Let’s look at the diagram below:
-
Security – even though you will not expose the Data Lakes to a broad audience, it is still very important that you think this aspect through, especially during the initial phase and architecturing. It’s not like relational databases, with an artillery of security mechanisms. Be careful and never underestimate this aspect.
-
Governance – monitoring and logging (or lineage) operations will become crucial at some point for measuring performance and adjusting the Data Lake.
-
Metadata – data about data, so mostly all the schemas, reload intervals, additional descriptions of the purpose of data, with descriptions on how it is meant to be used.
-
Stewardship – depending on the scale you might need, either separate team (role) or delegate this responsibility to the owners (users), possibly through some metadata solutions.
-
Master Data – an essential part of serving ready-to-use data. You need to either find a way to store your MD on the Data Lake, or reference it while executing ELT processes.
-
Archive – in case you have an additional relational DWH solution. You might face some performance and storage related problems in the area. Data Lakes are often used to keep some archive data that comes originally from DWH.
-
Offload – and again, in case you have other relational DWH solutions, you might want to use this area in order to offload some time/resource consuming ETL processes to your Data Lake, which might be way cheaper and faster.
-
Orchestration + ELT processes – as data is being pushed from the Raw Layer, through the Cleansed to the Sandbox and Application layer, you need a tool to orchestrate the flow. Most likely, you will need to apply transformations. Either you choose an orchestration tool capable of doing so, or you need some additional resources to execute them.
Other important aspects
You may think of Data Lakes as the Holy Grail of self-organizing storage. I have heard “Let’s ingest in, and it’s done” so many times. In fact, the reality is different and with this approach we will end up with something called Data Swamp.
Literally, it is an implementation of Data Lake Architecture storage, but it lacks either clear layer division or other components discussed in the article. Over time it becomes so messy, that getting the data we were looking for is nearly impossible. We should not undermine the importance of security, governance, stewardship, metadata and master data management.
A well-planned approach of designing these areas is essential to any Data Lake implementation. I highly encourage everyone to think of the desired structure they would like to work with. On the other hand, being too strict in these areas will cause Data Desert (opposite to Data Swamp). The Data Lake itself should be more about empowering people, rather than overregulating.
Most of the above problems may be solved by planning the desired structure inside your Data Lake Layers and by putting reliable owners in charge.
From our experience, we see that the organization of Data Lakes can be influenced by:
-
Time partitioning
-
Data load patterns (Real-time, Streaming, Incremental, Full load, One time)
-
Subject areas/source
-
Security boundaries
-
Downstream app/purpose/uses
-
Owner/stewardship
-
Retention policies (temporary, permanent, time-fixed)
-
Business impact (Critical, High, Medium, Low)
-
Confidential classification (Public information, Internal use only, Supplier/partner confidential, Personally identifiable information, Sensitive – financial)
Summing up
To sum up, let’s go over the main objectives, what implementing any Data Lake should accomplish. With the above knowledge, their explanation is going to be simple:
-
3 v’s (Velocity, Variety, Volume). We may operate on a variety of data, high in volume, with incredible velocity. The important fact is that velocity stands here not only for the processing time, but also for time to value, since it’s easier to build prototypes and explore data.
-
Reduced effort to ingest data (Raw Layer), delay work to plan the schema and create models until the value of the data is known.
-
Facilitate advanced analytics scenarios, new use cases with new types of data. Starting MVPs with data that are ready to use. This saves both time and money.
-
Store large volumes of data cost efficiently. There is no need to think if the data will be used, it can be stored just-in-case. Properly governed and managed data can be collected till the day we realize that it might be useful.




