


Today, business information systems are increasingly data-heavy. The constant growth of companies generates a geometrical influx of data coming from various dispersed and heterogeneous sources. This technological change has made extracting value from the data a toilsome and problematic endeavor.
Here is where process mining comes to the rescue.
Process mining may bring to mind associations with data mining, Big Data, and AI algorithms. In part, this is true –
process mining is based on specific types of data (entry logs), which can map the processes in your company by using certain algorithms (e.g., machine learning).

Figure 1. A simple rendition of the process mining procedure.
Accenture has carried out a survey among more than 1,000 business process professionals, and they revealed that 88% of companies that use machine learning (for data mining, process mining etc.) have improved by over 200% in their business process main KPIs. At the same time, only up to 9% of them use AI’s full potential.
Moreover, 34% of the professionals have stated that thanks to AI algorithms, they were able to reveal hidden value and processes in their companies’ data, allowing for better decision-making and to provide additional services or products. 82% have also become able to find solutions to previously unseen problems.
Process mining is exactly the methodology designed to unearth hidden problems and their solutions (Fig. 2).
.jpg?width=676&height=633&name=Process%20Mining%20Models-graf1-1024x959-(Compressify.io).jpg)
Figure 2. An exemplary map of processes mined in a company working in the domain of supply chain.
In this post, we are going to describe process mining and shortly explain how can it be used in practice.
1. Why is process mining taking over?
2. Process mining models and use cases
3. Process mining steps in a successful project
1. Why is process mining taking over?
Process mining is a mix of data mining and machine learning, but the truly original input of it is modeling business processes. Process mining is supposed to track down, analyze, and improve processes that are not only theoretical models, but that are identifiable in business practice. Therefore,
the most crucial difference between process mining and data mining or more traditional Business Process Modelling is extracting actual process maps from data.
In contemporary systems, this knowledge is extracted mostly from event logs (more about it below). They usually consist of detailed entries of activities, including the information who has undertaken them and when. These events may comprise all sorts of activities in a company – starting from the clients’ purchases, their website usage, through various company departments processes, to the management decision-related processes.
This data can be acquired from various sources, including not only the P2P processes, but also ticketing or legacy systems.
It is crucial that process mining is entirely data-driven, which means that if we are planning to discover the map of processes in some domain, then the processes need to:
-
Leave some kind of trace in our systems (log entry needed),
-
Be repeated a proper amount of times – obviously, the data requires to be regular in order for you to be able to find patterning it.
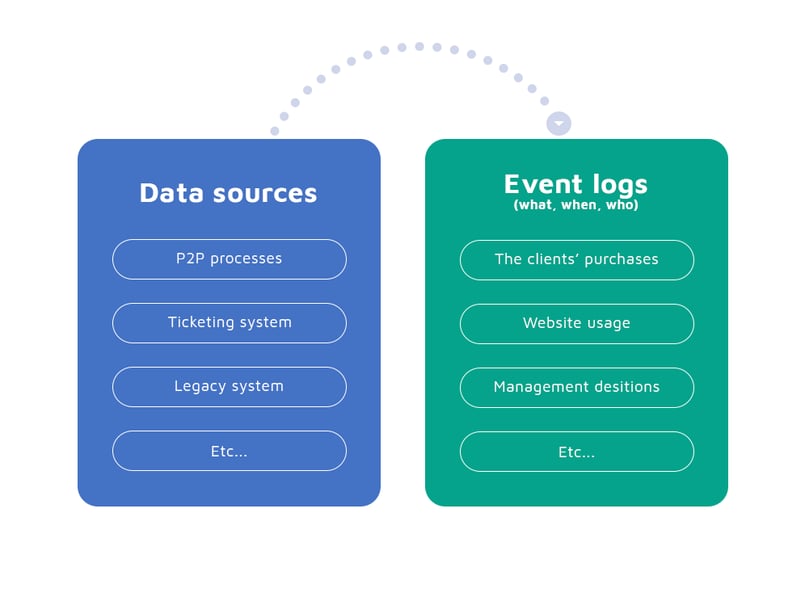
Figure 2. Event log-based knowledge extraction system.
Process mining is therefore useful for companies that experience problems with complex process. Moreover, process mining is capable of creating an overview of the way processes are actually performed when there is a discrepancy between them and the assumed processes (when what we think is happening is actually untrue).
Process mining utilizes data (in the form of logbook entries) that is already stored by companies. Often it is not implemented into other analytical processes, since they frequently comprise a mere byproduct of other IT processes. Therefore, very often this is the first attempt to approach this type of data structurally and systematically. Naturally, by acquiring knowledge about such processes, you may identify bottlenecks in your company operations, such as extended execution or waiting times. This information is especially important in businesses that operate in time-constrained domains, like food processing and manufacturing, or supply chain.
2. Process mining models and use cases
Based on event logs, process mining can deliver 3 types of information.
-
Discovery – this is a truly data-driven approach. It consists of producing a process map, based on event logs without any assumptions or additional/external information about the model of the process. In more developed logs, there may be additional information present, for example referring to human resources. In such cases you may obviously extract more knowledge. It could be, for example, a social network and the way people interact in the company.
-
Conformance – this is a“reality check” method, where you check whether your model, or process map, conforms to reality, or the events recorded in the log. Here with the use of process mining, you can check if there are any breachesin the rules. For example, if there are any outliers or abnormal behaviors of your clients or employees, or maybe even potential fraudsters. Process mining may also reveal whether these deviations are significant or whether they may be ignored. A banking system would be a natural candidate for this type of process mining.
-
Enhancement – this method enriches the standard discovery and conformance processes with an improvement of your theoretical process map. Therefore, you may for example devise two models – and check against the event logs – which of them represents the real-world scenario. You may also decide to modify your model with enhancements, or add new aspects to it by, for example, reviewing timestamps in your event logs, and find out about bottlenecks, frequencies of purchases, supply delays, service stoppage etc.
3. Process mining steps in a successful project (case study)
As an example, let us review in practice a process mapping system of a supply chain procedure in a medium/large company.
There are three main problems when it comes to supply chain company management:
-
Delivery failures – including delivery to a wrong location, damaging shipped goods, and delivery of a wrong amount of goods or wrong goods altogether.
-
Warehousing costs – includes errors in sorting and inventory records, and problems with locating the origin of an issue in a specific warehouse.
-
Difficulties in logistics management – lack of knowledge about supply chain performance, nonoptimal ERP due to the lack of mapping all processes in the chain, lack of proper visibility.
Process mapping can deal with the above-mentioned issues, by equipping manufacturers with a“just-in-time” perspective on inventory, and cost reduction obtained through a decrease of safety stocks and excessive work-in-process inventories.
There are two well-known Process Mining methodologies: Process Diagnostics Method [PDM], adapted for healthcare environments, useful for providing a fast and broad process overview and the L* life-cycle model, which is more complex than PDM, providing more functionalities, like process improvement and operational support.
While describing our case study, we will follow the methodology of PM2, since PDM and L* suffer from some problems, like lack of iterative analysis and the scarcity of practical guidelines.
PM2 defines the following
six steps of a proper Process Mining Models project: planning, extraction, data processing, mining and analysis, evaluation, and process improvement and support.
Thus, our case study of a supply chain company undertaking a process mining change may follow this scheme:
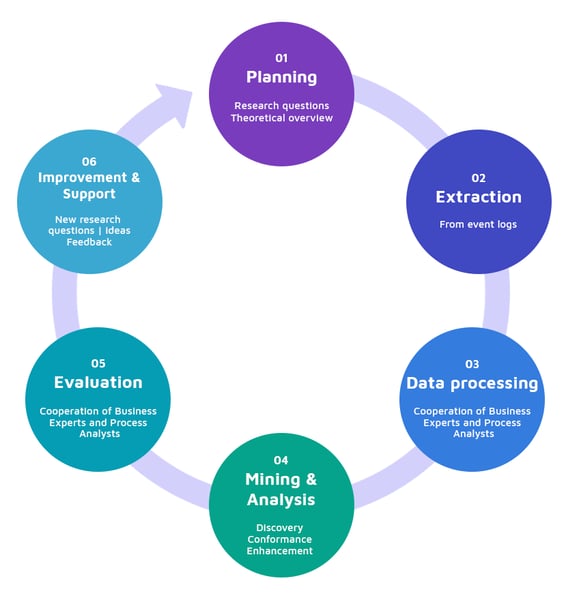
Figure 3. Process Mining architecture based on the PM2 methodology.
When applied skillfully, the Process Mining methodology, may allow you to map processes, find deviations from usual proceedings, and to discover bottlenecks and opportunities for improving your processes. There is still plenty of chances to refine Process Mining and to employ it successfully, especially in such process demanding areas like supply chain.


