


In our previous article, we explored the landscape of data management, and how organizations are navigating it with new and existing approaches as well as combinations of both. We also tackled its significance now, what with the need to handle increasing volume and complexity in data, advancements in technology, and the pressure to maximize the business value of data assets.
A data lakehouse or (augmented) a unified data and analytics platform is touted as the best of both worlds: the scalability and flexibility of data lakes and the reliability and consistency of data warehouses. It best fits organizations that want a centralized and unified structure for managing data, but it might not address all use cases. The technologies behind are still nascent, too, so despite maturing rapidly, its future costs, development, and maintenance might pose challenges.
There are two other approaches that can be considered: data fabric or data as a service and data mesh or data as a product.
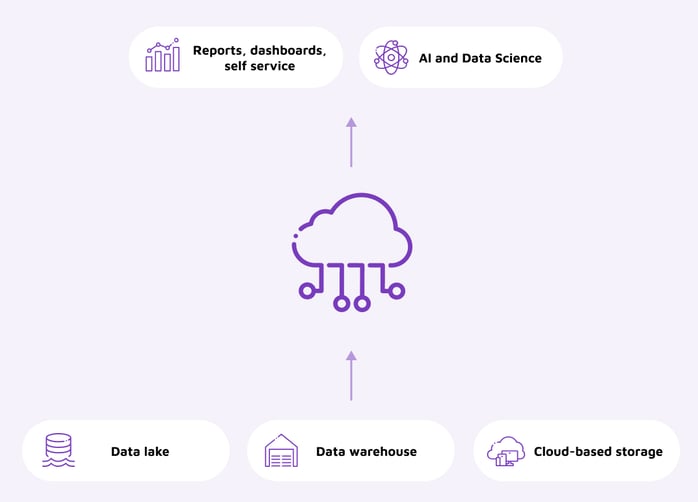
Figure 1. A sample visualization of data fabric or data as a service
Data fabric or data as a service
Data fabric in a nutshell: Automation of data management through metadata activation
The term “data fabric” was reportedly coined by data management systems provider NetApp in 2016, though its definition and design have varied over the years.
A data fabric is an integration platform that provides a unified view of all data across different systems and applications. It allows companies to deliver data at scale, making it easy for business users to access the data they need without having to worry about the underlying infrastructure or data source. This solution is ideal for companies that need to integrate data from multiple sources and want to simplify the process of accessing and managing data delivering data as a service in the organization.
One of the key promoters of this concept, Gartner, defines data fabric in terms of delivering data management at scale through automation by using active metadata, knowledge graph, and machine learning among others.
In relation to data fabric, we also see commonly used the concept of data as a service, which is used by organizations as the approach to provide an agile and automated or semiautomated provision of all data assets in an organization in a unified format.
Data team/organization structure: One of the key objectives is to achieve a high level of automation and reduce dependency on highly skilled engineers, so the data team/organization structure will mostly move toward decentralization.
Complexity of change: High complexity from both organizational and architectural points of view
Why the next choice?
Consider a data fabric as your “what’s next” choice if you:
-
Want to scale data management through automation or by enabling nontechnical resources (citizen X roles) to perform tasks on their own.
-
Want to use the existing data systems without having to migrate or move to a system for consumption.
-
Need to accelerate the access to your data assets across the organization.
-
Need to standardize and unify data management (providing a single framework to manage data across multiple and disparate deployments reduces the complexity of data management).
-
Want to reduce time to market of new use cases.
-
Want to keep a composable architecture and assemble best-fit solutions components.
Considerations and risks:
While data fabric (as defined by Gartner) is a very promising concept, it is possibly the most complex to implement out of the three paradigms described in this article. Key points to consider:
-
Gartner has defined the data fabric as still transformational, with an emerging technology, low current market penetration, and with a time to mainstream of 5-10 years. It is therefore a very promising concept, but it's important to understand where your organization is in terms of delivering a data fabric. This will depend on the following aspects:
-
Maturity and readiness of your metadata or metadata management practice
-
Availability of knowledge graph experts
-
Change in culture from centralization to decentralization of data
-
-
Data fabric cannot be provided by one single tool or technology but rather requires assembly of different components. It's crucial to evaluate the technology maturity of components selected to deliver data fabric and integration into the overall data ecosystem.
-
Despite its name, Microsoft Fabric is, per Gartner’s definition, not a data fabric but should instead fall under the UDAP category. Both aim to bring data together and unify, but one is focused on all data unification while the other is focused on unification of Microsoft products to deliver end-to-end analytics.
8787.png?width=647&height=473&name=MicrosoftTeams-image%20(1)8787.png)
Figure 2. A sample visualization of data mesh or data as a product
Data mesh or data as a product
Data mesh in a nutshell: Distributed data ownership through data as a product
The term data mesh was coined by Zhamak Dehghani in 2019 while she was working as a principal consultant at the technology company Thoughtworks.
Data mesh is a sociotechnical approach to building a decentralized data architecture using a domain-oriented, self-serve design. It allows companies to treat data as a product and enables cross-functional teams to take ownership of their own data domains. In 2022, it reached considerable popularity but has somehow lost momentum in the last months. This is possibly due to organizations realizing the difficulty with its implementation, thereby leading to other designs or concepts appearing based on the data mesh principles.
In its 2022 data management hype cycle, Gartner regarded data mesh as obsolete before plateau, arguing that the original data mesh concept will be obsolete before it reaches what Gartner calls the “plateau of productivity.” That doesn’t mean it is dead, but it might die out, or be absorbed or recast via another innovation. Gartner has now put a lot of emphasis on explaining that data mesh and data fabric are not competing concepts but rather are complementary.
Offspring/spin-offs to other concepts: While many organizations struggle to envision implementing the full data mesh in its purest form, many are adopting the data mesh principles in their existing data management capabilities and focusing on delivering data as a product through a self-service platform such as a data marketplace. A data marketplace serves as the solution which allows for a frictionless exchange of data products between teams who own and produce the data (data producers or data provisioners) and those who need to consume the data products (data consumers or data subscribers).
Other names which companies are using for delivering the same are “data as an asset” or “data as a resource.”
Data team/organization structure: Decentralized cross-functional domain teams
Complexity of change: High complexity from both organizational and architectural point of view, long-term implementation
Why the next choice?
A data mesh or managing data as a product is your “what’s next” choice if you are looking to:
-
Eliminate dependency on specialized central IT teams and bottlenecks.
-
Solve data quality issues caused by dysfunctional operational and analytical data teams.
-
Want to increase value of your data assets and eliminate/avoid the creation of data swamps.
-
Improve data usage measurement and value realization.
-
Manage data by teams with the business domain knowledge and closest to the source.
-
Distribute data responsibility to people who are closest to the data to support continuous change and scalability.
-
Reduce data delivery time and accelerate time-to-market of data analysis.
-
Enable teams to search and consume data assets in a standard way and format with little or no IT assistance.
-
Improve data standardization and governance.
Considerations and risks:
-
The definition and alignment of what a data product means for your organization should be the first step in adopting this approach. It can be interpreted and understood in different ways.
-
Many organizations confuse the term “domain” with functional or business units. It is key to define and establish what is a domain and what data it will own.
-
Governance, in particular data ownership, is a key aspect of this model. Possibly one of the most challenging areas is identifying/defining data owners and what it means to be a data product owner. It’s necessary to ensure your organizational readiness and the willingness of domain teams to accept data ownership. This might require gradual ownership decentralization.
-
The ideal setup requires the creation of cross-functional teams (including operational and analytical data teams). This might require a considerable culture and organizational change.
-
The move to a data mesh or a data-as-a-product approach can represent a big architectural and organizational change in your company, which will require high support across the organization. It's important to get the buy-in of key teams involved before moving with the implementation.
Recommendations on data management
In conclusion, when it comes to the question of "What's next in data management?", the answer is no longer simple. Companies now have three possible solutions to choose from, each with its own benefits and challenges.
.png?width=1920&height=1080&name=MicrosoftTeams-image%20(2).png)
Figure 3. A summary of the three data management paradigms/approaches
By evaluating their specific needs and requirements, companies can determine which solution is best for them. The key is to be forward-thinking and to embrace new approaches to data management that can help unlock the full potential of their data.
Based on how companies are adopting these paradigms, there is a clear tendency for organizations to deliver a data-as-a-product operating model and simplify their architecture with a data lakehouse. Data fabric, as shared by Gartner, is still at its early stages of maturity and readiness, but it is worth considering long-term in terms of automation and scalability.
Getting started with data management solutions
When deciding on the best solution for your organization, it’s important that you first build a common understanding in your company of what these paradigms are and what benefits they will offer to your existing data ecosystem. Match the solution to your specific needs and challenges and remember that your best next answer could be a combination of a few options.
Then, for the chosen solution, it's very important to build a case, including defining what is the expected value and benefits for your organization and the KPIs you will use to measure how value is realized, and networking across the organization so you can ensure the right support and funding.
Activate your target solution by starting from small, initial use cases. Deliver the first use case that will benefit from the chosen solution, measure and validate KPIs defined, and promote the value delivered in order to attract the next use cases.
Scale the solution to other use cases and keep improving the approach, always making sure that the company is realizing the expected benefits. Lastly, make sure you stay informed about the latest trends and solutions in the market since we are certainly at a key point of transformation in data management.
Lingaro’s technology consulting practice provide global brands and enterprises advisory and guidance on data management transformation. Fill our contact form and explore how you can realize the full value of your enterprise’s data — from data maturity assessment, 360-degree analytics diagnostics, data investment road map, and data platforms to data governance.